隨著人工智能技術的迅猛發展,法律咨詢領域正迎來數字化轉型的新浪潮。本項目通過Python技術棧,構建一個集法律咨詢大數據分析與智能服務推薦于一體的實戰項目,旨在提升法律服務的效率與精準度。以下將分步驟介紹項目核心內容。
一、項目概述
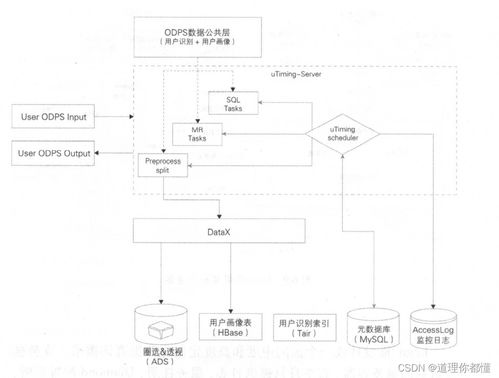
本項目聚焦于法律咨詢領域的大數據處理與智能分析,通過收集和分析海量法律案例、法規條文及用戶咨詢數據,構建一個支持智能問答、趨勢預測和服務推薦的一體化平臺。用戶可輸入法律問題,系統將自動匹配相關案例、法規,并通過機器學習模型生成個性化建議。
二、數據處理服務
數據處理是項目的基石,主要包括數據采集、清洗、存儲和特征工程等環節。
- 數據采集:利用Python的requests、BeautifulSoup等庫,從公開法律數據庫、政府網站和咨詢平臺抓取結構化與非結構化數據,如案例判決書、法規文本和用戶咨詢記錄。
- 數據清洗與預處理:使用pandas和NumPy進行數據去重、缺失值處理和格式標準化。對于文本數據,采用自然語言處理(NLP)技術,如jieba分詞、TF-IDF向量化,以提取關鍵特征。
- 數據存儲:選用MySQL或MongoDB存儲結構化數據,同時結合Elasticsearch實現高效檢索,確保數據可擴展性和快速訪問。
- 特征工程:通過特征選擇和降維技術(如PCA),構建用于分析和建模的數據集,提升后續模型的準確性。
三、大數據分析與AI應用
基于處理后的數據,項目集成多種AI技術以實現深度分析。
- 智能問答系統:利用預訓練語言模型(如BERT或GPT變體),構建法律問答模塊。用戶輸入問題后,系統通過語義匹配和知識圖譜檢索,返回精準答案和引用來源。
- 趨勢分析與預測:應用時間序列分析和機器學習算法(如ARIMA或LSTM),分析法律熱點變化趨勢,例如預測某類案件的增長概率,輔助決策制定。
- 情感分析與案例分類:使用NLP技術對用戶咨詢文本進行情感分析,識別用戶情緒傾向;通過聚類算法(如K-means)對案例自動分類,提高數據組織效率。
四、智能服務推薦
推薦系統是項目亮點,它基于用戶行為和內容特征,提供個性化法律建議。
- 協同過濾與內容推薦:結合用戶歷史咨詢數據和相似案例,采用協同過濾算法(如基于用戶的CF)和內容推薦方法,生成相關服務或律師推薦列表。
- 實時推薦引擎:利用Spark Streaming或Flask框架構建實時API,用戶每次交互后,系統動態更新推薦結果,確保時效性。
- 評估與優化:通過A/B測試和準確率、召回率等指標,持續優化推薦模型,提升用戶體驗。
五、技術實現與工具
項目主要使用Python及相關庫:
- 數據處理:pandas, NumPy, Scikit-learn
- NLP與AI模型:Transformers(Hugging Face), spaCy, TensorFlow/PyTorch
- 數據存儲:SQLAlchemy, PyMongo
- 可視化:Matplotlib, Seaborn(用于分析結果展示)
- 部署:Docker容器化,結合Flask或FastAPI構建RESTful API,便于集成到Web或移動端。
六、項目價值與展望
本實戰項目不僅提升了法律咨詢的智能化水平,還為法律從業者和普通用戶提供了高效、低成本的解決方案。可擴展至多語言支持、實時語音咨詢和區塊鏈數據安全等領域,進一步推動法律科技的創新。
通過這個項目,開發者可以掌握Python在大數據與AI領域的實戰技能,同時為法律行業數字化轉型貢獻價值。無論是初學者還是經驗豐富的工程師,都能從中獲得寶貴的實踐經驗。