在當今的數據密集型應用中,緩存技術已成為提升系統性能、降低數據庫負載的關鍵手段。緩存與數據庫之間的一致性問題,卻是數據處理服務中一個復雜且常見的挑戰。當數據在緩存和數據庫中出現不一致時,可能導致用戶看到過時、錯誤的信息,進而影響業務邏輯的正確性和用戶體驗。
一致性問題的主要根源
緩存與數據庫不一致的根本原因在于兩者是獨立的存儲系統,且數據更新操作通常無法在單個原子事務中完成。主要場景包括:
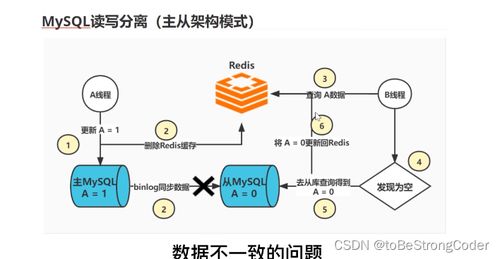
- 更新順序與并發:在高并發場景下,對同一數據的“讀”和“寫”操作可能以難以預測的順序交織進行。例如,先更新數據庫成功,但更新緩存失敗或延遲,后續的讀請求可能仍從緩存中獲取到舊數據。
- 緩存失效策略:常用的策略如“先更新數據庫,再刪除緩存”(Cache-Aside 或 Lazy Loading)并非萬無一失。在極端并發下,一個線程在更新數據庫后、刪除緩存前,另一個線程可能讀取了舊的數據庫值并重新加載到緩存中,導致緩存被“污染”為舊值。
- 數據同步延遲:在分布式系統中,數據庫主從復制存在延遲。如果應用從從庫讀取數據并寫入緩存,而主庫的更新尚未同步到從庫,緩存中就會存入舊數據。
- 復雜的業務邏輯:一個業務操作可能涉及多個數據實體的更新,確保所有這些更新在緩存和數據庫中都保持原子性和一致性非常困難。
對數據處理服務的影響
對于專門的數據處理服務(如ETL管道、實時計算引擎、API服務層),不一致性問題會帶來直接沖擊:
- 計算準確性受損:如果服務依賴于緩存數據進行分析、聚合或業務規則判斷,臟數據會導致計算結果錯誤。
- 服務可靠性下降:不一致可能表現為間歇性的數據錯誤,難以排查和復現,降低了服務的SLA(服務水平協議)。
- 系統復雜性增加:為了緩解一致性問題,往往需要在服務代碼中引入復雜的同步邏輯、重試機制或補償事務,增加了開發和維護成本。
主流解決方案與實踐
沒有“銀彈”能解決所有一致性問題,通常需要根據業務對一致性、性能和復雜度的要求進行權衡和選擇。
- 合理設置緩存過期時間(TTL):為緩存數據設置一個較短的生存時間,強制定期從數據庫刷新。這是一種最終一致性方案,簡單有效,適用于對一致性要求不非常嚴格的場景(如熱點新聞、商品描述)。
- 優化緩存更新策略:
- Cache-Aside(旁路緩存):應用代碼顯式管理緩存。讀時未命中則從數據庫加載;寫時先更新數據庫,然后刪除(而非更新)緩存。這是最常用的模式,但需注意前述的并發漏洞。
- Write-Through(直寫):寫操作同時更新緩存和數據庫(通常在緩存層中實現)。這保證了強一致性,但所有寫操作都承受數據庫的延遲,性能有損耗。
- Write-Behind(后寫):寫操作只更新緩存,再由緩存異步批量寫入數據庫。性能極高,但存在數據丟失風險(緩存崩潰),一致性最弱。
- 引入分布式鎖或隊列:對于關鍵數據,在更新時使用分布式鎖,確保“讀-更新數據庫-刪緩存”這一序列操作的原子性,防止并發干擾。更復雜的方案可以將數據庫更新和緩存操作通過消息隊列串行化處理。
- 采用數據庫變更日志捕獲(CDC):使用如Debezium、Canal等工具監聽數據庫的Binlog或WAL,將數據變更事件發布到消息隊列。然后由一個獨立的緩存維護服務消費這些事件,來更新或失效緩存。這實現了緩存與數據庫的準實時解耦同步,一致性高,對業務代碼侵入小。
- 容忍延遲與版本控制:對于某些場景,可以接受短暫的不一致。可以為數據增加版本號或時間戳,客戶端或服務端在發現數據版本過舊時,可以觸發一次刷新或提示用戶。
給數據處理服務的設計建議
- 評估一致性需求:明確業務對數據一致性的真實要求(強一致、最終一致、會話一致),避免過度設計。
- 緩存分層與降級:區分核心業務數據(高一致性要求)和輔助數據(可接受延遲),采用不同的緩存策略。確保在緩存系統故障時,服務能優雅降級至直接訪問數據庫。
- 監控與告警:建立完善的監控,追蹤緩存命中率、數據庫與緩存的數據差異(如通過定期抽樣對比),并設置告警。
- 標準化與封裝:在數據處理服務框架中,將緩存訪問邏輯(包括讀寫、失效策略、異常處理)封裝成統一的組件或中間件,減少業務代碼中的重復和錯誤。
緩存與數據庫的一致性是數據處理服務架構中必須慎重對待的問題。通過深入理解問題根源,結合業務場景選擇合適的策略組合,并輔以良好的設計、監控和運維,才能在享受緩存帶來的性能紅利的將數據不一致的風險控制在可接受的范圍內。