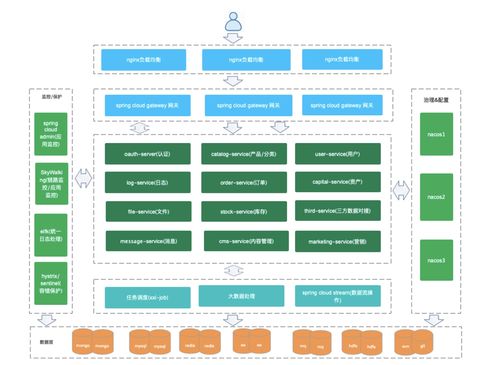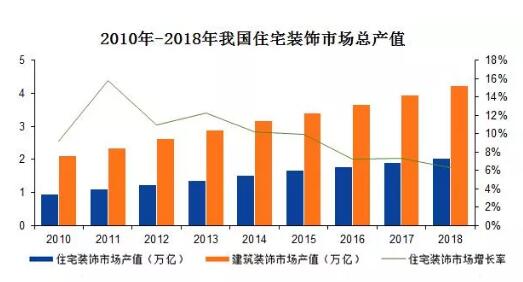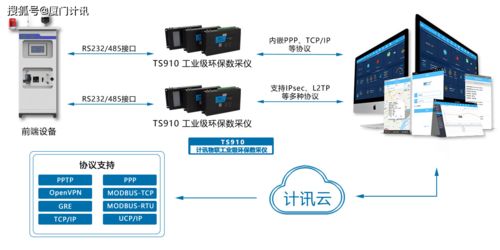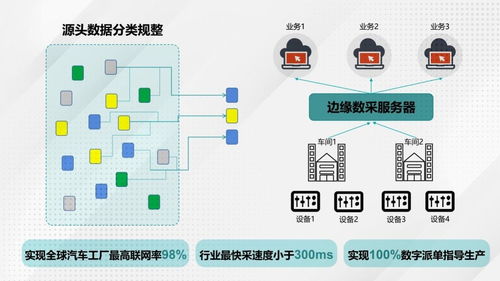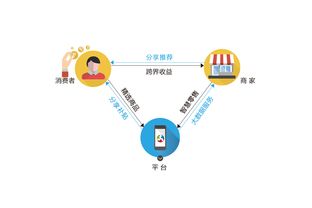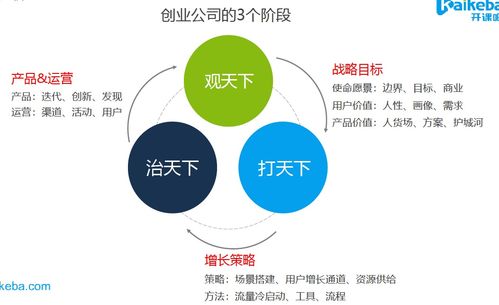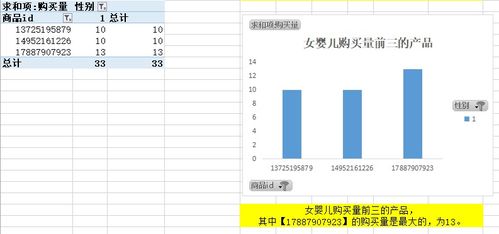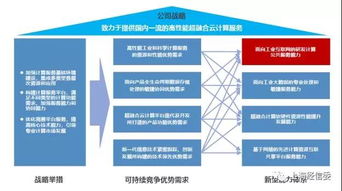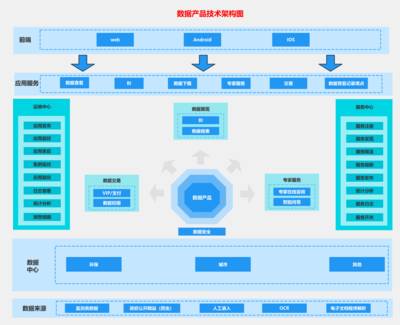
隨著數字化時代的快速發展,數據處理服務已成為數據產品的核心支撐。一個高效、穩定且可擴展的技術架構對于數據處理服務的成功至關重要。本文將深入剖析數據處理服務的系統架構圖,從數據采集到最終應用,全面解析各層次的功能與設計原則。
一、架構概述
數據處理服務的系統架構通常采用分層設計,主要包括數據采集層、數據處理層、數據存儲層和數據服務層。每一層獨立完成特定任務,并通過標準接口與其他層交互,確保系統的模塊化、可維護性和可擴展性。
二、數據采集層
數據采集層負責從多種數據源收集原始數據,包括:
- 日志采集:通過工具如Fluentd、Logstash等收集應用日志。
- 數據庫同步:利用CDC(Change Data Capture)技術實時同步關系型數據庫變更。
- API接口:集成第三方數據源,通過RESTful API或消息隊列獲取數據。
- 流數據接入:支持Kafka、Pulsar等消息隊列,處理實時數據流。
該層設計需注重數據格式統一、可靠性保障和低延遲要求。
三、數據處理層
數據處理層是架構的核心,負責數據的清洗、轉換、聚合和計算。常見組件包括:
- 批處理引擎:使用Spark、Flink等框架處理海量歷史數據,支持ETL(Extract, Transform, Load)流程。
- 流處理引擎:如Apache Flink或Storm,實現實時數據處理,滿足低延遲業務需求。
- 數據質量監控:集成數據校驗規則和異常檢測,確保數據準確性和一致性。
- 任務調度系統:通過Airflow或DolphinScheduler等工具,自動化管理數據處理任務。
該層強調高性能、容錯能力和資源調度優化。
四、數據存儲層
數據存儲層根據數據特性和訪問需求,選擇不同類型的存儲方案:
- 數據湖:基于HDFS或云對象存儲(如AWS S3),存儲原始和半結構化數據,支持靈活分析。
- 數據倉庫:采用Snowflake、BigQuery或ClickHouse,優化OLAP查詢,服務BI和報表需求。
- 實時存儲:使用Redis或Cassandra,支持高并發讀寫和緩存加速。
- 元數據管理:通過Atlas或DataHub等工具,維護數據血緣和治理信息。
存儲層設計需平衡成本、性能和數據生命周期管理。
五、數據服務層
數據服務層將處理后的數據暴露給上層應用,主要包括:
- API網關:提供統一的REST或GraphQL接口,實現數據查詢和訂閱服務。
- 數據可視化:集成Tableau、Superset等工具,支持自助分析和儀表盤展示。
- 安全與權限:通過RBAC(基于角色的訪問控制)和加密技術,保障數據安全。
- 監控與告警:結合Prometheus和Grafana,實時監控服務性能和可用性。
該層注重用戶體驗、低延遲和高可用性。
六、架構設計原則
在構建數據處理服務架構時,應遵循以下原則:
- 可擴展性:采用微服務和無狀態設計,便于水平擴展。
- 容錯性:通過冗余部署和故障恢復機制,確保系統穩定運行。
- 數據一致性:在分布式環境中,使用事務或最終一致性方案。
- 成本優化:根據數據冷熱特性,實施分層存儲和計算資源動態調整。
七、總結
數據處理服務的技術架構圖不僅是系統實現的藍圖,更是數據驅動業務的核心基礎。通過分層設計和模塊化組件,企業能夠高效處理海量數據,支撐智能決策和創新應用。未來,隨著AI和邊緣計算的發展,架構將向更智能、更分布式的方向演進,持續賦能數據產品生態。